

2022年2月24日,ACL2022公布录用结果,北京大学数字人文研究中心唐雪梅同学关于跨时代分词的论文被ACL2022主会录用,该论文也是首篇在自然语言处理国际顶级会议中以古汉语分词为研究任务的文章。以下为大家介绍论文主要内容:
That Slepen Al the Nyght with Open Ye! Cross-era Sequ
作者:唐雪梅,王军,苏祺*
类型:Long paper
摘要
语言演化遵循渐变的规律,随着时间的推移,语法、词汇和语义逐渐发生了变化,导致了历时的语言鸿沟。然而,许多的文本中经常掺杂着不同时代的语言,这给自然语言处理任务带来了障碍,如分词和机器翻译等。汉语是一门历史悠久的语言,但以往的汉语自然语言处理工作主要集中在特定时代的任务上。因此,在本文中提出了一个跨时代的汉语分词(CWS)学习框架 CROSSWISE,我们使用 Switch-memory(SM)模块来整合特定时代的语言知识。在四个不同时代的数据集上的实验表明,每个数据集的分词结果都有了显着的提升。进一步的分析还表明,SM模块可以有效地将时代知识整合到神经网络中。
研究背景
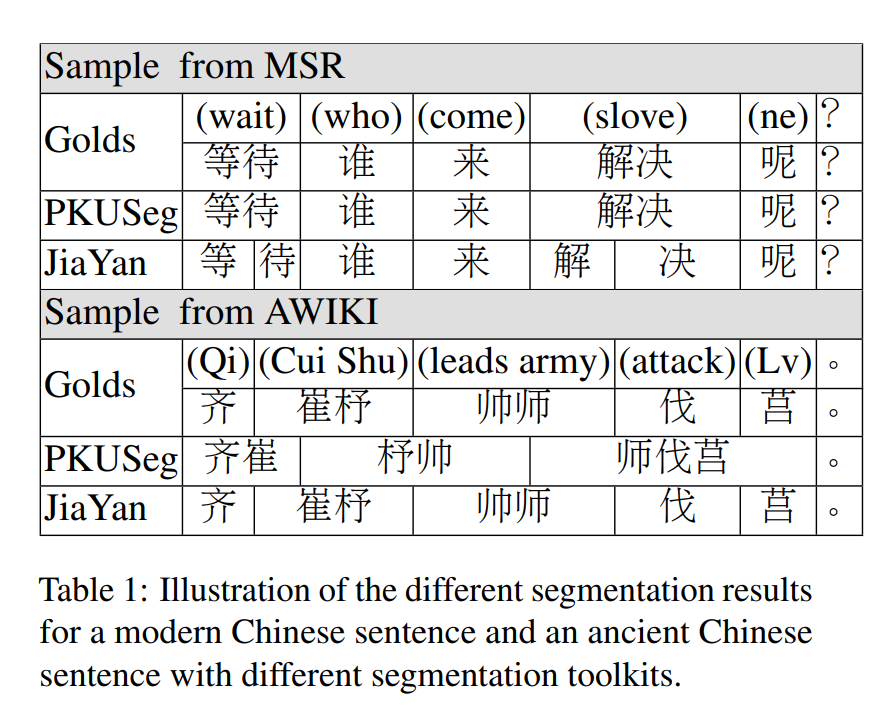
汉语被列为世界上最古老的语言之一,在其悠久的历史中发生了许多变化。它经历了各种化身,可以分为上古汉语,中古汉语,近古汉语和现代汉语四个时期。值得注意的是,大多数中文 NLP 任务都倾向于现代汉语。以汉语分词为例,以往的许多方法主要集中解决现代汉语的分词问题,并取得了令人满意的结果。虽然近几年来古汉语的CWS已经引起人们的注意,但语言混合的文本的处理仍然是一个悬而未决的问题。如Table 1所示,PKUSeg是一个用现代汉语语料库训练的汉语分词器,可以正确分词现代汉语句子,但应用于古汉语时准确率急剧下降。而古汉语分词器 JiaYan在古汉语文本上表现良好,但在现代汉语上表现不佳。因此,有必要开发合适的模型来解决跨时代的 NLP 任务。
研究贡献
– 本文是第一个在汉语分词任务中引入跨时代学习的研究,其中通过多任务架构共享所有参数。共享编码器用于捕获不同时代的数据集之间的共有特征。本文的单一模型可以根据不同的时代的句子产生不同的分词粒度。
– Switch-memory 机制用于将特定时代的知识整合到神经网络中,这有助于提高Out-of-Vocabulary(OOV)单词的召回率。并且本文提出了两种切换器模式hard-switcher 和 soft-switcher来控制每个记忆单元中将有多少信息被输入到模型中。
– 本文在四个不同时代的汉语分词数据集上的实验结果表明,每个数据集的性能都获得了显着的提升。进一步的分析还证实,我们的模型对于古汉和现汉混合的句子分词是非常灵活的。
提出方法
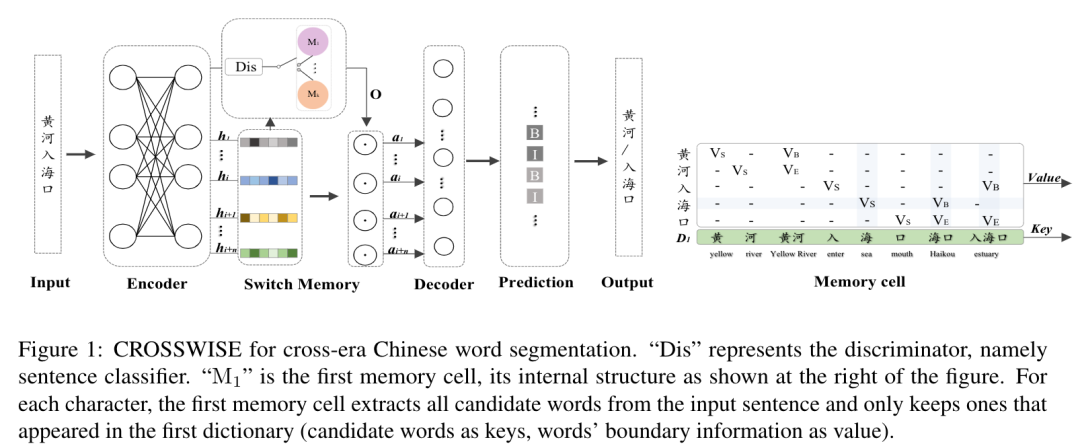
我们提出了 CROSSWISE(CROSS-ear Segmentation WIth Switch-mEmory),这是一个处理跨时代汉语分词(CECWS)任务的学习框架。该框架将特定时代的知识与 Switch-memory 机制相结合,以改进时代混合文本的 CWS。更具体地说,我们联合训练汉语分词和句子分类任务,以预测切分结果和时代标签。我们利用 Switch-memory 模块来整合不同时代的知识,它由key-value memory networks和 一个switcher 组成。key-value memory networks 由多个记忆单元组成,用于存储特定时代的语言知识。句子鉴别器被认为是一个switcher ,控制着每个记忆单元中有多少信息将被集成到模型中。对于每个存储单元,我们将词典中的候选词和词边界信息映射到key和value。
我们在四个不同时代(上古、中古、近古、现代)进行实验,通过分析实验结果发现,本文的模型在不同时代的数据集上都有比较好的分词效果,并且和前人的工作相比,也有比较明显的提升。消融实验结果进一步证明提出的SM模块能够提高不同时代数据集的F1值和OOV召回率。
应用价值
-
Gold answer: 唯/其/如此/,/天津市/“/鱼/与/熊掌/兼/得/”/的/实践/也/就/分外/值得/人们/重视/。
(from <新闻>)
-
Without SM: 唯/其/如此/,/天津市/“/鱼与熊掌/兼/得/”/的/实践/也/就/分外/值得/人们/重视/。
-
Ours: 唯/其/如此/,/天津市/“/鱼/与/熊掌/兼/得/”/的/实践/也/就/分外/值得/人们/重视/。

本次ACL论文收录展示北京大学数字人文研究中心在古汉语自然语言处理技术的最新进展。我们将再接再厉,一如既往的保持学习研究的热情,扎实开展实践研究,利用数字化技术方法为人文领域研究注入新动能。欢迎大家继续关注实验室的学术动态!
本篇文章来源于微信公众号:数字人文开放实验室