转载请注明“刊载于《数字人文研究》2021年第3期”;参考文献格式:陈涛. 目标检测在数字人文图像中的应用尝试[J]. 数字人文研究, 2021, 1(3): 39-50.全文PDF已在编辑部网站http://dhr.ruc.edu.cn上发表,此处注释及参考文献从略。
摘 要
图像已成为数字人文研究新的热点,而图像标注是图像知识传递和价值揭示的主要途径。目标检测作为一种计算机视觉和图像处理领域的技术,可快速批量实现图像中目标对象的定位与分类。基于目标检测相关原理,本次尝试是将视觉目标标注工具VoTT和多维度图像智慧系统MISS结合,形成完整的图像应用生态流程。同时提出了图像多层标注模型框架——包含图像层、对象层(内容和标签)、语义层三层四个维度,其中标注区域的选定和对象层的标签使用了VoTT自动标注的结果。最后通过案例对所提框架和技术进行了论证,以期为数字人文图像研究提供更多的应用视角。
关键词
目标检测;数字人文;图像标注;国际图像互操作框架
作 者
陈涛,中山大学信息管理学院副教授,Email:chent283@mail.sysu.edu.cn
0
引 言
数字人文是近年在人文学科各领域中逐渐兴起的研究趋势,强调学科之间的紧密关联,具有很强的交叉性。国内数字人文研究已经走过了十个年头,一批批学者围绕数字人文思想的引入以及数字人文研究与实践的本土化做了持续探索。“新文科”的提出也赋予了数字人文更大的研究和应用空间。《教育部社会科学司2020年工作要点》提出将启动高校文科实验室建设,而数字人文较强的综合性、交叉性、实践性正是新文科实验室可尝试的方向和落脚地之一。数字人文研究中常用的资源类型多样,涉及文本、图像、音频、视频等多种资源模态。相比其他资源类型,图像资源有着天然的优势,较之文本和音频,图像更为直观;较之视频,图像更为轻量级,传阅方便。运用好图像蕴含的大量知识,可以起到汇聚文化知识、梳理文化脉络、讲好文化故事的作用。而图像标注是使图像知识得到体现的最主要途径,是让图像开口说话,实现图像“活化”、价值提升的关键环节,也是图像类资源人机交互的主要方式。通过图像标注可以将更多的显性知识与隐性知识、内部知识与关联知识、通用知识与专家知识叠加于方寸之间,实现图像内容的语义增强。然而,传统人工标注的方式工作量大、效率低,借助计算机深度学习算法则可以实现大量图片的快速自动标注,极大缩短图像标注时间,提升研究效率。
1
文献综述
针对图像资源的研究已成为数字人文近几年的热点方向之一,众多学者从不同视角进行了探索。首先,不少学者对图像资源建设的宏观框架展开研究。王若宸等基于Panofsky和Shatford的图像学理论模型构建了一种专门面向非遗图像的语义描述框架,并针对该框架设计了一个完整的图像上下文关键词提取流程。王晓光等基于图像元数据和信息需求理论,针对敦煌壁画数字图像这一特定领域,提出了语义描述框架和领域主题词表相结合的数字图像内容语义描述方法;并在后续的实践中证明了该框架作为图像深度语义标注参照基准的可行性。曾子明等提出了一种面向数字人文的图像语义描述模型,根据用户认知特征制定图像语义结构化描述框架,并利用多方法组合进行语义特征词抽取与映射。陈涛等提出了图像开放五星模型,并结合国际图像互操作框架和AI技术构建图像资源语义化研究框架,探索图像资源的数字化、文本化、数据化和语义化的实现路径。Cheng X F针对中国传统工艺品种的图像集进行结构分析和提出语义描述框架。Li X H针对叙事图像,提出了语义表示框架“ESImage”,该框架主要采用分层架构,逐步组织图像中的语义信息,在基于图形的语义数据模型的支持下进行描述。
其次,部分学者的研究聚焦于图像标注方法、工具和模型。杨佳颖等选取民国报刊《新闻报》上的越剧广告,结合语义模型和IIIF框架,对广告图像进行标注,以更为准确地揭示图像所涵盖的文本信息。赵海英等针对当前图像多标签标注方法只能标注图像内容信息(本体),而不能同时标注图像寓意信息(隐义)的问题,提出了一种基于多任务学习的双层多标签标注模型(MTL-DMAM)。徐雷等借助模块化本体设计思想,结合开放标注协同框架(OAC),以情节、实体、活动、情境为核心,设计了一个适用于叙事型图像的深度语义标注本体模型。周知等提出了一种四层架构的面向数字人文图像资源的知识组织模型,并对模型中的语义描述部分利用本体的技术与方法进行语义组织框架构建。宋宁远等收集了五款图像语义标注软件,并对比分析了它们的语义标注与发布功能以及数据结构模型,总结出此类工具的特点和不足。陈金菊等采用文献调研法,对Eakins模型、Jaimes&Chang模型、Kong模型和Panofsky模型进行了总结,剖析了它们在图像语义标注中的优缺点。陆泉等按照图像语义标注方法的发展阶段,对基于文本的人工图像标注方法、自动图像标注(AIA)方法、结合相关文本的Web图像标注方法以及大众标注方法四种图像语义标注方法进行了述评,指出所存在的语义鸿沟问题,并探讨了未来的发展趋势。泽农·迪奥多西欧(Zenonas Theodosiou)等通过对众包平台上图像标注的质量分析,指出标注的质量受到图像内容本身和标注所使用的词典影响。米亚萨尔·蒙德尔·阿德南(Myasar Mundher Adnan)等详细研究了手动、半自动和自动图像标注方法,同时调研了注释系统的评估措施。
从上述调研可见,在数字人文领域已有大量的研究针对图像资源展开,其中理论研究居多,但并未发现有较为成熟的图像标注平台或工具来支持大规模的数字人文图像研究;所涉及的图像标注模型和方法,也都以小范围的人工标注为主,关于自动标注的研究较少。
与此同时,作为近十年来人工智能领域取得的最重要的突破之一,深度学习在计算机视觉和图像处理方面已取得巨大成功;ImageNet、COCO等大规模图像数据库的出现也对图像资源深度学习研究的浪潮起了巨大的推动作用。这其中,基于深度学习的目标检测(Object Detection)技术为实现大量图像的快速自动标注提供了可能。目标检测是一种与计算机视觉和图像处理相关的技术,用于检测数字图像和视频中某一类语义对象(如人、物、建筑等)的实例,目前已成为计算机视觉领域的一个研究热点。赵永强等在广泛文献调研的基础上,从双阶段、单阶段目标检测算法的改进与结合角度、模型训练方式和网络结构角度对深度学习目标检测方法进行了总结与梳理,并对目标检测技术有待解决的问题与未来研究方向做出预测。Zhao Z Q等也对基于深度学习的对象检测框架进行了回顾,通过实验分析来对多种方法进行比较。段仲静等对卷积神经网络框架、anchor-based模型和anchor-free模型三个主流的目标检测模型进行了梳理,并总结了不同目标检测方法的研究进展。胡君林针对注意力机制在图像区域权重分配策略不当、图像特征存在过多冗余信息的问题,提出了一种基于Faster R-CNN算法的改进方法,用以提取图像的目标区域特征。于宁等提出了一种由深度学习中间层特征表示图像视觉特征、由正例样本均值向量表示语义概念的图像标注方法。史瑞·斯里瓦斯塔瓦(Shrey Srivastava)比较了SSD、Faster R-CNN、YOLO三种图像处理算法,评估了相关性能,并根据准确率、精度和F1分数等参数分析了它们各自的优势和局限性。
数字人文研究经常面对大量如民国报刊、历史老照片、书画文物、古籍文献等数字化后的图像资源,这些图像中蕴含着非常丰富的内容,如印章、画押、人物、山水等,如果能将这些对象目标自动抽取和标注出来建立专题子库,将会串联起不同图像资源,释放图像更大的数据价值。本研究尝试将目标检测应用于创建完整的数字人文图像研究平台,即为服务于此类设想的实现,无疑具有一定的前瞻性和探索性,并有广阔的应用前景。
2
目标检测技术原理及工具
对于种类多样、位置不定、大小不一、形状各异的目标对象,如何快速精准地完成检测和识别是目标检测任务需要解决的主要问题,即确定目标对象所在位置及大小(定位)和确定目标对象的类别(分类)。由于深度学习技术已成为直接从数据中学习特征表示的强大策略,并在通用对象检测领域取得了显著突破,因此目前主流的目标检测算法主要是基于深度学习模型,大体分为One-Stage(单阶段)和Two-Stage(双阶段)两类。
(1)One-Stage目标检测算法不需要产生候选框(Region Proposals),可以通过一个阶段直接产生物体的类别概率和位置坐标值。比较典型的算法有YOLO、SSD和CornerNet。
(2)Two-Stage目标检测算法将检测问题分为两个阶段,首先产生候选框,包含目标大概的位置信息,随后在第二个阶段对候选区域进行分类和位置精修。比较典型的算法有R-CNN、Fast R-CNN、Faster R-CNN等。
目标检测模型的主要性能指标是检测准度和速度,One-Stage速度相比Two-Stage较快,但准度较低。本研究选取的标注工具采用的是Two-Stage中的Faster R-CNN算法,其原理见图1。

图1 Faster R-CNN算法原理图
首先将图像(P×Q)缩放至固定大小(M×N)传入整个网络,随后的算法可分为CNN层、RPN层和全连接层,各自的原理和作用为如下。
(1)CNN层中,Faster R-CNN使用一组基础conv+relu+pooling层提取图像的特征(Feature Map),该Feature Map被共享用于后续的RPN层和全连接层。
(2)RPN层中,RPN网络用于生成候选框(Region Proposals),该层通过Softmax判断候选框属于前景(Foreground)还是背景(Background),从中选取前景候选框(因为物体一般在前景中),并利用bounding box regression调整候选框的位置,从而得到特征子图,即proposals。
(3)全连接层中,ROI Pooling用来收集输入的Feature Map和Proposal,综合这些信息提取proposal feature map,送入后续的全连接层。最后通过分类和回归两个分支来实现对该候选目标类别的判定和位置的确定。
计算机视觉任务中除了目标检测,常见还有图像分类和图像分割,三者共同组成了图像分析的三个层次:分类、检测、分割。简单来说,图像分类就是判断出图像中有什么(含有哪些分类),如图像中有人、羊、狗、猫等;目标检测除了指出图像中有什么,还需要指出在哪里(用矩形框标定目标方位);图像分割则是将数字图像细分为多个图像子区域(像素的集合)的过程,常分为语义分割与实例分割。相比目标检测,图像分割对目标区域的选定更为精细,通常精确到目标边界(边缘),常应用于自动驾驶汽车、人机交互、虚拟现实等领域,这也意味着图像分割所需要的技术和算法更为复杂。基于课题要解决的问题是对图像对象目标的定位,因此选取目标检测作为探讨对象。
目标检测领域,常用的开源图像标注工具有计算机视觉标注工具VCAT,可视化对象标注工具VoTT、DataTurks、Make-Sense、LabelMe、LabelImg、VGG VIA等。VoTT(Visual Object Tagging Tool)是微软发布的用于图像目标检测的标注工具,它是基于javascript开发的,因此可以跨Windows和Linux平台运行,并且支持图像与视频数据标注,支持信息以CNTK、Pascal VOC、CSV等格式导出,可用于神经网络训练、计算机视觉、目标识别等。因此本研究选用VoTT与现有的MISS平台(Multi-dimensional Image Smart System,多维度图像智慧系统)进行整合。MISS为自主设计和研发的图像应用平台,采用语义网、关联数据、本体、知识图谱等语义框架和技术构建,可以实现超大尺寸图像的在线组织、复用、标注、关联与发布。目前MISS平台已得到上海图书馆、上海交通大学、华东师范大学、南京大学、南通大学等众多科研机构数字人文学者的关注。
3
VoTT+MISS整合框架
3.1
图像应用生态流程
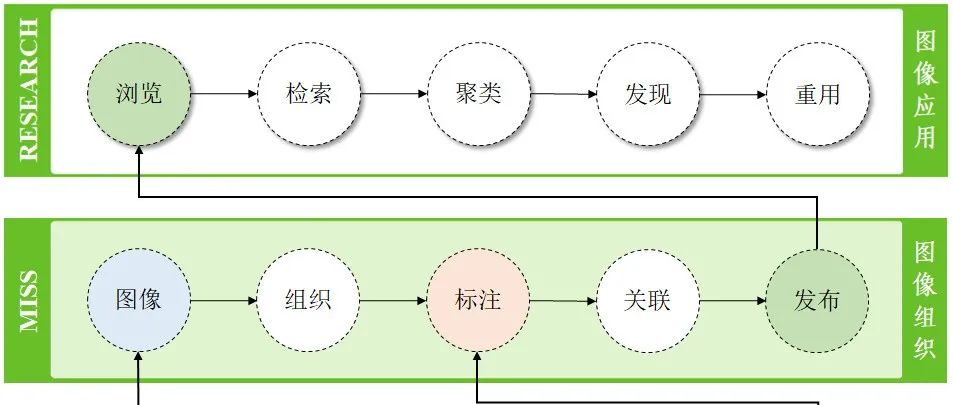
目前的数字人文研究缺少针对图像资源的专门研究平台和工具,调研中提及的针对标注方法和框架的研究大多停留在理论模型和原型构建中,并且自动化程度不高,对于批量开展数字人文图像资源项目的支撑度不够。完整的数字人文图像研究平台至少应集图像管理与维护、图像组织与复用、图像标注与关联、图像发布与赏析等多功能于一体,形成一套图像应用生态。VoTT与MISS平台的结合,为图像应用生态方案提供了实施的可能。整体流程如图2所示,按照功能自下而上分为图像标注、图像组织和图像应用三层。

图2 VoTT+MISS图像应用生态流程图
(1)最底层主要借助VoTT工具对图像中的目标对象进行机器为主、人工为辅的标注。VoTT中提供了基于CNTK训练的Faster R-CNN模型进行自动标注,然后辅以人工校正,这样大大减轻了工作量。校正后的标注资源同样可以导出用于进一步的机器学习,以获得更为快速精准的自动标注。
(2)中间层主要利用MISS平台进行图像组织,图像经过转换和组织后,才能得到更为高效的应用和分析。MISS平台基于国际图像互操作框架(IIIF)的要求和标准构建,以分布式图像资源的交互与共享为理念,目前支持国内外众多科研机构和文化遗产机构图像资源的在线复用与组织,为图像领域的研究提供了大量的数字和数据资源。MISS平台可以导入VoTT中的标注(分类)内容,并可对图像内容进行进一步的多级标注、深度关联和语义发布。
(3)最上层为图像知识应用层,可对MISS平台中发布的图像进行具体的研究应用,包括图像资源的分享浏览、标注内容的全文检索、标注分类统计分析、图像甚至目标对象关联知识发现,以及在线图像资源的再利用。
3.2
图像多层标注框架
图3为MISS平台与VoTT工具结合后实现的图像多层标注的框架结构,两者在标注的维度和侧重点上有所不同:VoTT工具实现以机器为主的对目标对象的快速定位和分类,而MISS平台将从图像层、对象层和语义层三个层级共四个维度对图像进行多级人工标注。

图3 MISS与VoTT结合的标注框架
(1)图像层标注主要是针对组织后的图像资源(一张或多张图像组合)的元数据描述,常注入的元数据信息涉及题名、创作时间、创作者、资源描述、材质、尺寸、分类、收藏机构、版权声明等。
(2)对象层标注则是深入到图像中的具体目标对象,可以从内容和分类两方面展开。内容抄录可以对图像进行文本识别、目标对象描述、故事情节叙述、局部纹理及形状描述、色彩说明等;分类标签则可以给目标对象加上特定的标签,如人、物、景等。这方面的标注恰好是VoTT工具标注的优势所在,通过VoTT工具快速获得的目标对象区域和分类标签可以很好地补充对象层的标注,大大降低人工标注的工作量。
(3)语义层标注主要是建立起目标对象与外部资源的链接,以获得更多的对象知识,增强图像内容和语义。通常将用RDF三元组方式建立的知识关联称为语义关联,获得知识的过程称为语义标注。借助MISS系统和本体服务中心提供的本体资源可以很好地进行语义标注。建立好关联关系后,就可以在线获得所关联对象更多的相关知识。
3.3
MISS+VoTT的标注实现
VoTT标注的分类信息将以JSON格式导入MISS平台,两者之间需要在部分字段上建立关联,图4显示了VoTT与MISS标注字段间的差异和关联关系。导入时将对VoTT文件中path、tags和points字段进行重构,以符合MISS平台中的标注格式需求。其中path信息需要从本地图像的地址变更到MISS平台中该图像对应的在线发布地址image字段;tags为具体的分类标签,在MISS中为category字段;points为标记对象的区域(支持矩形和多边形形状),需要对应到area字段。

图4 VoTT与MISS标注字段差异与关联
类图以反映类结构和类之间关系为目的,用以描述软件系统的结构,是一种静态建模方法。图5为MISS中兼容VoTT标注的UML类图,其中,AnnotationImport类的doPost()方法可实现提交的标注文件(VoTT工具的JSON格式文件)的解析,解析时通过getVoTTAnnotation()和getMISSAnnotaton()方法进行标注信息的提取;convertVoTT2MISS()方法用来建立VoTT标注格式与MISS标注格式之间的映射。MISSBean和VoTTBean类定义了标注信息的元数据字段。接口(interface)类StoreAdapter实现具体标注内容的存储和索引。JenaStore为接口具体的实现类;除了使用Jena进行存储外,还可以使用Sesame和Solr等存储方式来实现。AutoAnnoUtils类将依据Web注释数据模型(Web Annotation Data Model)要求生成标注信息(generateJson()方法),其中getArea()方法用来生成标注对象的边界(bounding box),convertRectoSVG()则用SVG(可缩放矢量图)渲染标注区域。

图5 MISS中实现VoTT标注的UML类图
4
案例与分析
接下来将结合具体案例来阐述本研究所提标注框架和技术的可行性,以期为数字人文图像研究提供更多的解决方案和思路。案例相关图像来源于网络,主要为含有人物类对象的民国历史老照片图像。
4.1
VoTT自动标注
采用VoTT工具对所下载图像中的人物进行批量自动检测和定位。图6为批量定位与分类标注截图,图像中有五个人被自动框选和分类;一张图像被标定后,如切换到另外的图像,新图像中的人物目标将会被自动定位和分类(需要设定Auto Detect)。待所有老照片中的人物被定位和标记后,可以导出JSON格式文件,文件中将会包含所有标注的方位和分类标签。

图6 VoTT实现批量定位与分类标注
以图6中最左边人物为例,JSON中相应的标注内容为:

4.2
MISS二次标注
如前文所述,MISS平台支持VoTT标注文件的导入,导入后会将VoTT格式转为MISS平台中的标注格式,即依据Web注释数据模型进行组织和存储。
图7为导入VoTT标注文件后MISS平台上的展示效果,可以看出VoTT标注时有个儿童并没有被准确定位和识别,对此,在MISS平台上可以进行人工修正和二次标注。标注后的效果如图8所示,这里框定了儿童目标对象,同时也标记了目标内容和分类标签。可见,通过VoTT自动标注加MISS二次标注这种途径可以在较短的时间内实现图像目标对象的准确标注。元数据层面的注入一般通过导入元数据字段的方式批量生成,语义层面的标注常采用RDF三元组对相关资源进行关联,这两类层级的标注本文不做具体讨论。

图7 VoTT标注在MISS中的展示

图8 MISS二次标注
4.3
应用前景:目标专题知识库建设
图像应用生态流程中最上层为图像应用,快速定位和分类图像中具体的目标对象在数字人文研究和资源建设方面具有重要的现实价值,也存在一些潜在的应用前景,目标专题知识库建设即是其一。
图9为经过VoTT标注和MISS组织后抽取的民国老照片中的人物汇聚图,到这里就可以将同类目标从图像中实时抽取出来,建立相应的人物专题知识库。进一步,可经过特征提取在人物专题库之上建立特征库,实现人物图像的检索。Keras提供了诸多的预训练模型用来对图像进行特征提取,如VGG16、VGG19、ResNet50、InceptionV3等。进行图像比对时,采用同样的代码获取输入图像的特征向量,并采用相似度计算将所获取的特征向量与特征库中学习到的特征向量进行比较,获取最优的输出图像。检索到最优的特征图像后,可以查看该图像的具体来源,即来源于何张(或多张)图像以及在图像中的具体方位。

图9 人物标注实时汇聚图
在古籍、书画作品等文化遗产研究方面,这一路径也有着巨大的应用空间。比如,印章知识库。古籍、书画作品中存在大量的印章(也称钤印),这些印章是作品中不可缺少的组成部分。作为一种特殊的元素,印章包含了重要的版本信息,同时也反映了一本古籍、一件作品的流传轨迹,是鉴定文物价值的绝好依据。因此,对大量古籍和书画中的印章对象进行快速定位和提取,建立起印章知识库,将会在印章研究、文物鉴别、版本循证等方面起重要作用。
再如中国山水画知识库。中国山水画有着悠久的历史和深厚的文化底蕴,作为古老东方艺术的代表,集中展现了中国历史社会的变迁和中国人的人生观、价值观。《中国大百科全书·美术卷》将山水画分类为:青绿山水(金碧山水)、水墨山水(墨笔山水)、浅绛山水(淡着色山水)、小青绿山水、没骨山水。不同种类的山水画,因为赋彩、笔法、画法的不同而呈现出迥异的艺术风格和艺术面貌。如果能够将不同书画中的山水抽取和标记出来,构建山水画知识库,对于山水画法以及中国山水画史的研究将有显著的推进作用。
除了图像知识库的建设,本文所提方法还可以助推传统文化IP的创新发展。据《2018中国文化IP产业发展报告》,文化IP代表着某一类文化现象,中国传统文化具有鲜明的民族特色和丰富的内涵,有巨大的IP塑造空间;十九大报告也提出了“深入挖掘中国传统文化当代价值”的新目标。应用VoTT+MISS图像研究平台,从不同类型的资源中对中国各类传统文化元素进行快速检测和目标提取,如以传统书画中的“神兽”“祥云”“器皿”及古籍中的画押、文字符号等为目标对象,可以为IP设计提供大量的原生素材。可以说,围绕图像资源,数字人文研究潜力巨大。
5
结论与展望
图像是数字人文研究中重要的资源类型,图像标注是实现图像价值挖掘和传播的主要方式之一。图像中的内容只有对象化、数据化、精准化,才能更细粒度地建立图像之间的内在联系,构建真正的图像知识库。借助基于深度学习的目标检测技术进行图像目标对象的快速定位与分类识别,能够极大程度减少人工标注所带来的工作量,提高标注效率。本研究将使用目标检测技术的视觉目标标注工具VoTT与多维度图像智慧系统MISS进行了整合,是图像资源利用的重要尝试,并由此提出了完整的图像应用生态——包含图像从组织到标注、从发布到复用、从浏览到研究的全流程,为图像资源的研究与利用指出了一条鲜明的实施路径。文中案例部分提出的构建目标专题知识库的设想和愿景,必将在更多的数字人文研究中得到实现。
当然,本研究只是目标检测技术在数字人文领域应用的粗浅尝试,后续会在以下几个方面做进一步的深挖和探索。
(1)目标检测是以矩形框来定位目标区域,不能精准地标定目标实际轮廓,不能反映对象的多态性(方形、圆形、多边形等),如何进一步地进行语义分割且快速绘制目标精准轮廓、带来更好的用户体验,是本研究下一步探索的主要方向之一。
(2)对于人物的目标检测,本研究采用了属于Two-Stage 检测类型的Faster R-CNN算法支持的VoTT,下一步将尝试YOLO识别模型以获取更高效的检测效率。YOLO属于One-Stage检测类型,因此YOLO模型检测的速度较R-CNN系列模型要快很多。YOLO已经经历了许多不同版本的迭代,目前YOLO9000模型通过联合训练已能够检测9000种不同类别的目标,但是精度不是很理想。因此,如何根据目标对象(如印章、画押)训练模型也是下一步研究的方向之一。
编辑:李星玥
版式:贺谭涛

公众号账号:rucdh2019
网址:http://dh.ruc.edu.cn
邮箱:rucdh@ruc.edu.cn

中国人民大学数字人文研究中心集人民大学多学科优势,秉持融合文理、协同创新之理念,开展数字人文理论研究、实践探索、人才培养和学术交流。
原文始发于微信公众号(数字人文研究):目标检测在数字人文图像中的应用尝试